Overview
In this article, we will build an application where Kafka sends orders and returns data to Flink, which will be responsible for maintaining a live counter of the total items in our inventory for each product.
Kafka Producer
The Kafka producer is designed to send three different types of messages:
- Product Messages: These messages will be used to add new products to the system. Each message will contain details about a product, such as its ID, name, and initial quantity.
- Order Messages: These messages will be used to deduct from the number of available items in the inventory. An order message will specify the product ID and the quantity ordered, allowing Flink to adjust the inventory accordingly.
- Return Messages: These messages will add back items to the inventory. A return message will include the product ID and the quantity being returned, allowing Flink to update the inventory with the returned items.
Below is our code for the Kafka producer:
from kafka import KafkaProducer
import json
import time
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
security_protocol="PLAINTEXT",
value_serializer=lambda v: json.dumps(v).encode('ascii')
)
# Produce Data
def produce_data(topic, value):
producer.send(
topic,
value=value
)
product_value = {
"type": "product",
"product_id": 1,
"desc": "some data",
"cost": 12,
"quantity": 400
}
order_value = {
"type": "order",
"order_id": 1,
"product_id": 1,
"quantity": 3,
"total": 36
}
order_value_2 = {
"type": "order",
"order_id": 2,
"product_id": 1,
"quantity": 30,
"total": 360
}
return_value = {
"type": "return",
"return_id": 1,
"order_id": 1,
"product_id": 1,
"quantity": 20,
"total": 60
}
produce_data('product_topic', product_value)
time.sleep(2)
produce_data('order_topic', order_value)
produce_data('order_topic', order_value_2)
time.sleep(2)
produce_data('return_topic', return_value)
producer.flush()
Flink Consumer
To set up Kafka, follow these steps:
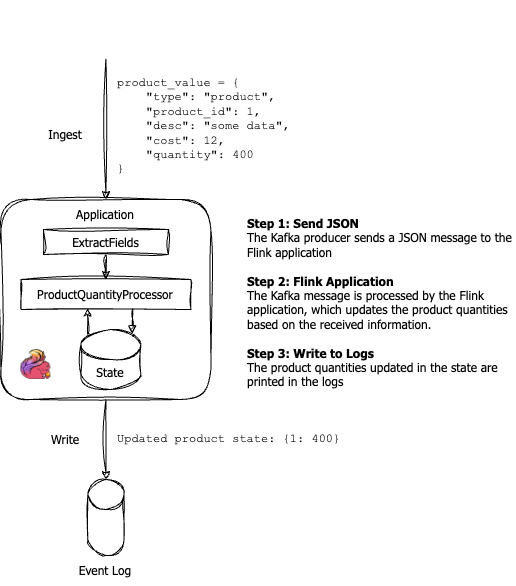
This Flink consumer continuously reads messages from Kafka and keeps track of product quantities in real time. By categorizing messages into product additions, orders, and returns, the system ensures that the inventory counts are always up to date. The use of state in the ProductQuantityProcessor class allows Flink to maintain the current inventory across streaming events, ensuring consistency even with the dynamic nature of Kafka messages. Below is the structure of how the code will function, with the Flink Kafka Consumer handling the real-time updates to the product quantities.
import json
from pyflink.datastream import StreamExecutionEnvironment, KeyedStream
from pyflink.datastream.connectors.kafka import FlinkKafkaConsumer
from pyflink.common.serialization import SimpleStringSchema
from pyflink.datastream.functions import MapFunction, KeyedProcessFunction
from pyflink.common.typeinfo import Types
from pyflink.datastream.state import ValueStateDescriptor
import logging
# ExtractFields is a MapFunction that parses JSON messages and extracts key fields.
# It takes a JSON string, converts it to a Python dictionary, and returns a tuple
# containing the product ID, message type (e.g., product, order, return), and quantity.
class ExtractFields(MapFunction):
def map(self, value):
data = json.loads(value)
return (data['product_id'], data['type'], data.get('quantity', 0))
# ProductQuantityProcessor is a KeyedProcessFunction that maintains and updates the state of product quantities.
# It processes messages based on their type ('product', 'order', 'return') and modifies the quantity in the state accordingly.
# The state is a map where product IDs are keys, and quantities are values.
class ProductQuantityProcessor(KeyedProcessFunction):
def open(self, runtime_context):
# Initialize the state that stores product quantities as a map of product ID to quantity.
self.product_state = runtime_context.get_state(
ValueStateDescriptor('product_state', Types.MAP(Types.INT(), Types.INT()))
)
def process_element(self, value, ctx: 'KeyedProcessFunction.Context'):
# Extract product ID, message type, and quantity from the incoming message.
product_id, message_type, quantity = value
product_state = self.product_state.value() or {}
# Handle different types of messages:
if message_type == 'product':
product_state[product_id] = quantity
elif message_type == 'order':
if product_id in product_state:
product_state[product_id] -= quantity
else:
logging.warning(f"Received order for non-existent product ID: {product_id}")
elif message_type == 'return':
if product_id in product_state:
product_state[product_id] += quantity
else:
logging.warning(f"Received return for non-existent product ID: {product_id}")
# Update the state with the modified product quantities and log the changes.
self.product_state.update(product_state)
logging.info(f"Updated product state: {product_state}")
# Initialize the Flink environment
env = StreamExecutionEnvironment.get_execution_environment()
# Kafka Consumer setup for all topics
kafka_consumer = FlinkKafkaConsumer(
topics=['order_topic', 'return_topic', 'product_topic'],
properties={'bootstrap.servers': 'localhost:9092', 'group.id': 'flink-group'},
deserialization_schema=SimpleStringSchema() # Deserializes messages as strings
)
# Stream source from Kafka consumer
stream = env.add_source(kafka_consumer)
# Process each message
processed_stream = stream \
.map(ExtractFields(), output_type=Types.TUPLE([Types.INT(), Types.STRING(), Types.INT()])) \
.key_by(lambda x: x[0]) \
.process(ProductQuantityProcessor())
# Execute the Flink environment
env.execute("Product Quantity Tracker")Running the Code
Once you have both the consumer and producer files ready, follow these steps to run the application: .
Output
Once the consumer is running successfully and the producer has finished sending messages, you can view the output in the Flink log files. Follow these steps to access the logs:
- Open your Flink installation folder.
- Navigate to the log folder.
-
Look for the log file named
flink-{username}-taskexecutor-{number}-{system_details}.local.log.
Updated product state: {1: 400}
Updated product state: {1: 397}
Updated product state: {1: 367}
Updated product state: {1: 387}